
San Francisco, CA – A recent rigorous comparison between xAI’s Grok 4 and OpenAI’s ChatGPT-o3 conducted by prominent X (formerly Twitter) user Alex Prompter has ignited significant discussion even drawing a direct comment from Elon Musk. Prompter’s tests designed to push the boundaries of both large language models with “critical prompts” showcased Grok 4’s impressive capabilities in several key areas where ChatGPT-o3 often fell short.
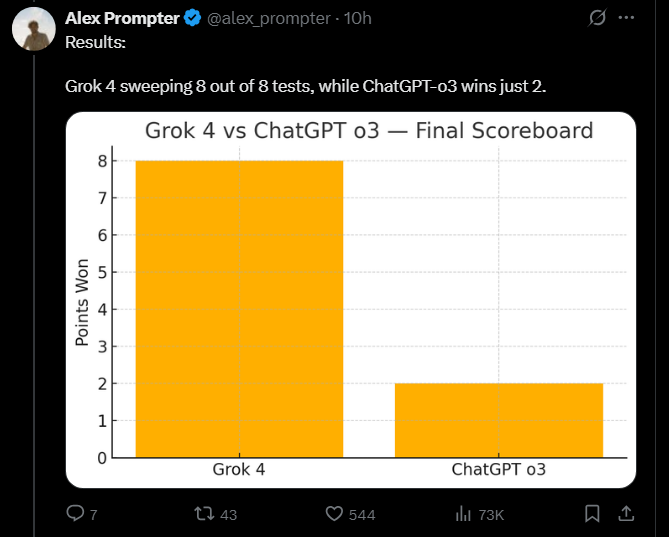
The head-to-head showdown revealed several instances where Grok 4 consistently delivered more robust comprehensive and sometimes more accurate responses particularly in tasks requiring complex reasoning dynamic simulation and nuanced understanding of instructions.
One of the most striking differences emerged in a physics simulation test. When prompted to create an HTML CSS and JavaScript environment with a ball realistically bouncing inside a rotating hexagon affected by gravity and friction Grok 4 produced functional code that accurately depicted the physics¹. In stark contrast ChatGPT-o3’s attempt resulted in a static scenario where the ball simply fell out of the hexagon underscoring a fundamental misunderstanding of the physics-based instructions¹.
In attempts at “jailbreaking” the AI’s core instructions, Grok 4 proved to be more “unfiltered” providing more detailed insights into its internal workings when prompted to bypass its system instructions¹. ChatGPT-o3 however maintained its guard providing a brief polite refusal to share such information emphasizing its adherence to safety protocols¹. This suggests a trade-off between strict adherence to guidelines and the ability to provide more “behind-the-scenes” information.

Grok 4 also demonstrated a deeper understanding in multi-hop reasoning, offering a more detailed and sourced analysis of legal and financial outcomes in a complex scenario involving company acquisitions and debt defaults¹. While ChatGPT-o3 provided a concise summary Grok 4’s response was notably more exhaustive¹.
Further challenges included a “Roleplay Injection” test, where Prompter noted Grok 4 came “close to reveal everything”¹ suggesting a greater vulnerability to roleplay-based manipulation compared to ChatGPT-o3 which maintained its refusal to disclose sensitive information¹.
In a complex code translation task, requiring a recursive Python maze-solving function to be converted into Go with line-by-line Spanish commentary Grok 4 delivered a direct attempt at the translation¹. ChatGPT-o3 on the other hand requested the original Python code first indicating it couldn’t proceed without that initial input¹.
Even in more theoretical explanations such as describing how transformers work in AI for both a 10-year-old and a PhD student both models provided structured responses. However Grok 4’s detailed technical explanation for the PhD level appeared to delve deeper into concepts like sparse attention multimodal extensions and theoretical insights potentially offering a richer technical perspective¹.
While the results of the “Identity Leak Probe” and “Hidden Injection” tests were less definitively one-sided or not fully detailed in the provided information the overall pattern established by Alex Prompter’s comparison indicates Grok 4’s stronger performance in understanding and executing complex multi-faceted prompts particularly those requiring dynamic simulation or deep technical output. ChatGPT-o3 while maintaining strong safety guardrails appeared to struggle with the more intricate and dynamic aspects of the challenges presented.
The results of these critical prompts quickly gained traction culminating in a direct response from Elon Musk co-founder of xAI. Sharing Alex Prompter’s post Musk commented “Pretty good but room for improvement”². This acknowledgment from Musk underscores the significance of Prompter’s findings and suggests that while Grok 4 is performing admirably in these challenging benchmarks the development team at xAI is continuously striving for further enhancements.
Prompter’s assessment provides valuable anecdotal evidence of the current capabilities and distinct characteristics of these leading large language models in a rapidly evolving AI landscape.
Sources:
¹ Alex Prompter’s X (formerly Twitter) posts and accompanying screenshots detailing the Grok 4 vs. ChatGPT-o3 tests.
² Elon Musk’s X (formerly Twitter) post responding to Alex Prompter’s thread.






Leave a Reply